
Paulo Afonso Lopes
O objetivo de muitas análises é avaliar a conformidade aos valores limites fixados em regulamentos ou em especificações comerciais. A conformidade pode exigir a quantidade de um mensurando especificado estar acima ou abaixo de um limite único de especificação ou dentro de um intervalo com um limite superior e um limite inferior.
Em alguns casos, o resultado, incluindo a sua incerteza de medição, será diferente do valor limite para que se possa afirmar que há conformidade; em outros, o grau de conformidade não estará claro e decisões deverão ser tomadas com base em critérios probabilísticos. Para o valor de uma amostra, há três cenários referentes a essas especificações: somente limite superior, somente limite inferior e limites inferior e superior.
Para o do desvio padrão da amostra, por ser medida de variabilidade, apenas o limite superior. Os exemplos referem-se somente a ensaios com um limite superior de especificação, em que a faixa de aprovação de resultados é aquela abaixo desse limite, que não deve ser ultrapassado.
Um problema a resolver
A Resolução 432 de 23 de janeiro de 2013 do Conselho Nacional de Trânsito (Contran) não permite nenhuma quantidade de álcool no sangue do condutor, que será autuado administrativamente por qualquer concentração de bebida. Entretanto, para caracterizar o crime previsto no art. 306 do Código de Trânsito Brasileiro (CTB), um dos critérios é o exame de sangue apresentar resultado igual ou superior a 6 (seis) decigramas de álcool por litro de sangue (6 dg/L), e as pessoas que decidem com base em limites legais devem ser capazes de responderem a perguntas do seguinte tipo: uma concentração de 6,1 dg de álcool por litro de sangue de um motorista é muito significativamente maior do que o limite legal de 6 dg/L?
As decisões podem ser baseadas somente no resultado pontual. Com base apenas no valor obtido na amostra observada, as situações e decisões que podem haver são as seguintes (Figura 1):
Casos 1 e 2. O resultado se encontra abaixo do limite superior de especificação: resultado CONFORME.
Casos 3 e 4. O resultado se encontra acima do limite superior de especificação: resultado NÃO CONFORME.
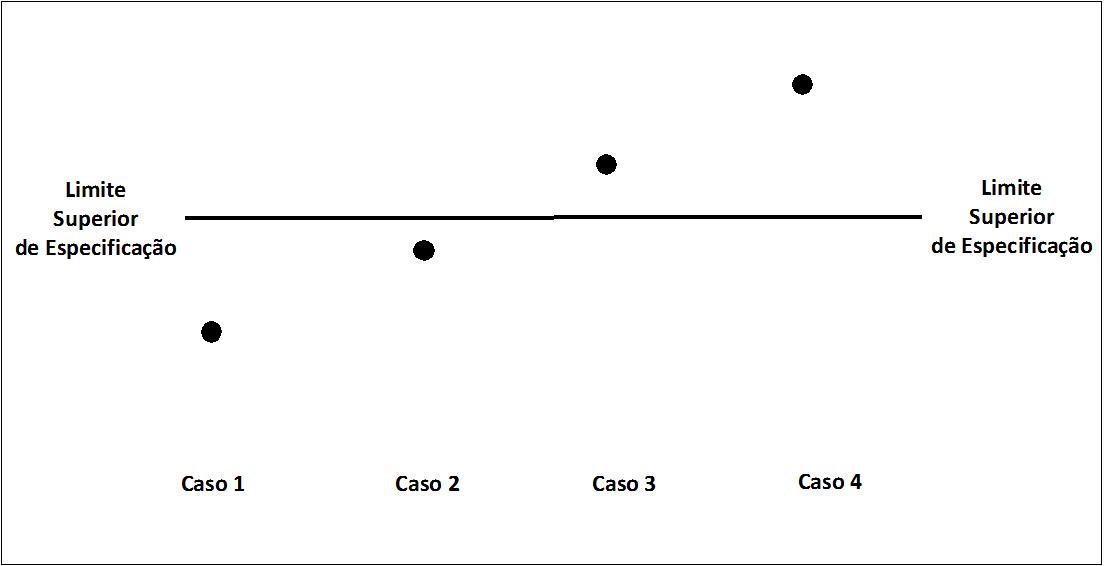
Figura 1 – Casos em que a decisão se baseia apenas no resultado pontual
Entretanto, não há a certeza de que o resultado (valor pontual) na amostra forneceu o valor da população. Nesse caso, retira-se uma segunda amostra para verificar, e o resultado é outro. Como saber onde está a verdade? Retira-se, então, uma terceira amostra, uma quarta, mais resultados diferentes, e assim por diante. Como resolver?
Ao se observar todos os resultados, verifica-se uma variação deles e, por meio dessa variabilidade, determina-se o denominado intervalo de confiança, no qual pode pertencer, com uma determinada probabilidade, o valor da população. As afirmações feitas a respeito do parâmetro da população sempre devem vir acompanhadas de um grau de confiança, ou grau de certeza; significando o quanto se está certo ao comunicar essa informação, que tem um risco, que é probabilidade associada a uma decisão errada.
A probabilidade do valor da população se encontrar no intervalo de confiança, centrado na estimativa pontual e com variação negativa e positiva em torno dessa estimativa pontual é, usualmente, igual a 95%. Isso quer dizer que há uma probabilidade de 95% do valor da população ser qualquer um dentro desse intervalo. Quando da estimativa de um resultado com sua incerteza de medição, esse intervalo passa a chamar-se intervalo de abrangência.
As decisões podem ser baseadas somente na amplitude do intervalo de abrangência. Todos os resultados analíticos têm a forma “C k.u” ou ” C U”, onde “C” é a melhor estimativa do valor da concentração do mensurando, k é o fator de abrangência, “u”, escrito em minúsculas, é a incerteza padrão, e “U”, escrito em maiúsculas, é a incerteza expandida, igual a k.u. O valor de “2k.u”, igual a “k.U”, é a amplitude do intervalo de abrangência, dentro do qual se encontra o valor da concentração com elevada probabilidade, usualmente 95%.
Tem-se as seguintes situações e decisões (Figura 2):
O resultado se encontra abaixo do limite superior de especificação, mas todo o intervalo de abrangência está abaixo desse limite: resultado CONFORME, embora haja uma probabilidade de 5% de ser não conforme.
O resultado se encontra abaixo do limite superior de especificação, mas o intervalo de abrangência contém esse limite superior, resultado pode estar CONFORME ou NÃO CONFORME, porque há uma probabilidade de 95% desse intervalo de abrangência conter o valor do parâmetro da população, ou seja, o valor da população pode estar acima do limite superior de especificação:
Semelhante ao Caso 2, em que o resultado se encontra acima do limite superior de especificação.
O resultado se encontra acima do limite superior de especificação, mas todo o intervalo de abrangência está acima desse limite: resultado NÃO CONFORME, embora haja uma probabilidade de 5% de ser conforme.
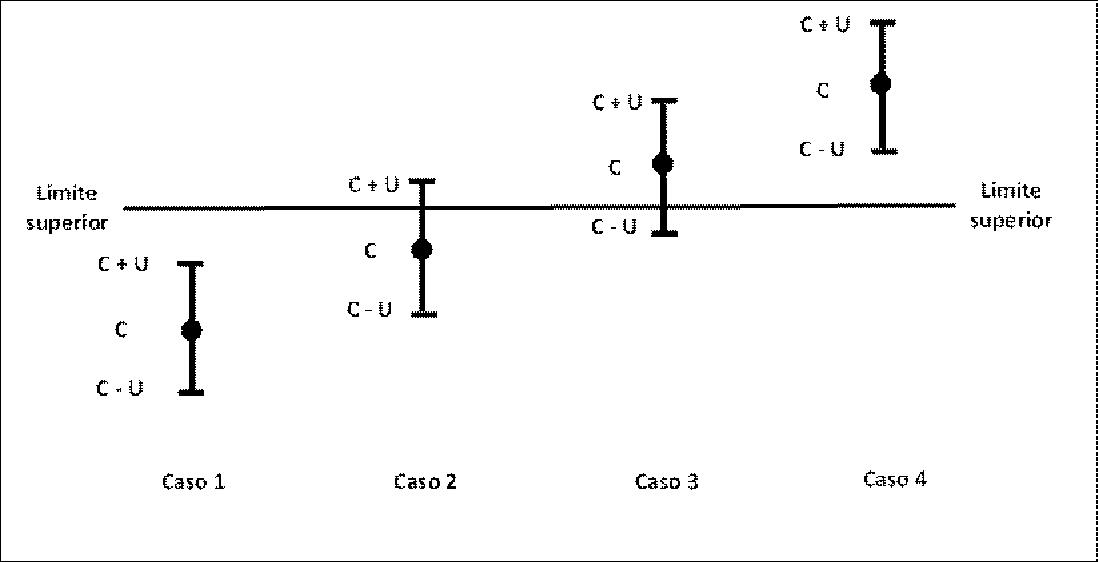
Figura 2 – Casos em que a decisão se baseia estritamente na amplitude do intervalo de abrangência
Para os Casos 2 e 3, tem-se duas situações de cada um deles: na primeira (Casos 2a e 3a), a probabilidade de que o resultado seja considerado CONFORME é “elevada” e, na segunda (Casos 2b e 3b), essa probabilidade de ser CONFORME é “baixa” (Figura 3).
A probabilidade do resultado ser considerado CONFORME denomina-se PROBABILIDADE DE CONFORMIDADE.
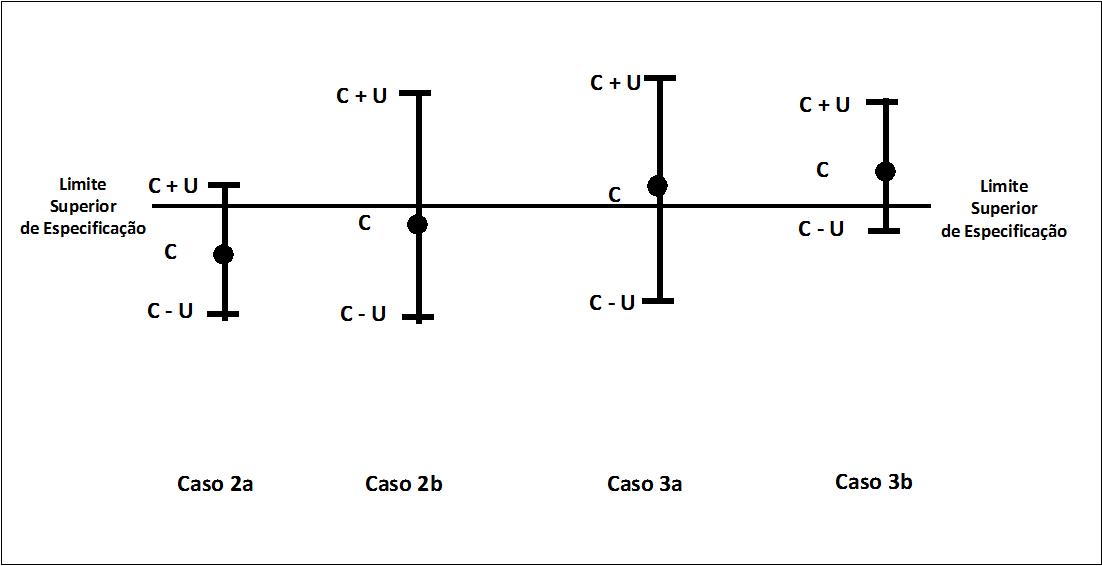
Figura 3 – Casos em que a decisão se baseia na posição do intervalo de abrangência
Pode-se fazer um exemplo numérico de decisões baseadas na amplitude do intervalo de abrangência. Nos casos legais, deve-se estar certo de que o limite foi excedido, ou seja, o limite de decisão para se agir não é, necessariamente, igual ao valor do limite superior de especificação.
Considere-se 6 dg/L como o limite superior para o nível de álcool no sangue de um motorista. Para as concentrações nominais de 3, 5, 7 e 9 dg/L, as seguintes incertezas de medição foram determinadas:
3,00 ± 1,32 dg/L
5,00 ± 1,98 dg/L
7,00 ± 2,06 dg/L
9,00 ± 2,20 dg/L
Na Situação 1, o intervalo de abrangência é de 1,68 a 4,32 dg/L, completamente abaixo do limite 6 dg/L, resultado CONFORME.
Na Situação 2, o resultado está abaixo do limite, o que pode levar à decisão de considerar o resultado como CONFORME. Entretanto, esse está se aproximando do limite e o intervalo de abrangência tem como limite superior 6,98 dg/L e, então, as amostras futuras devem ser examinadas com maior cuidado, porque há uma probabilidade de que a população exceda esse limite e o resultado seria julgado NÃO CONFORME.
Na Situação 3, o resultado encontra-se acima do limite superior de especificação, mas o valor da população se encontra no intervalo de abrangência, que vai de 4,94 a 9,06 dg/L. Por esse motivo, pode-se relatar que a amostra contém não menos que 4,94 dg/L e, por esse motivo, não se garante que o limite superior foi excedido e nenhuma ação seria tomada.
Na Situação 4, o intervalo de abrangência é de 6,80 a 11,20 dg/L, completamente acima do limite 6 dg/L, resultado NÃO CONFORME.
O conceito de “faixa de proteção” (guard band)
Como podem haver decisões diferentes, dependendo da posição do intervalo de abrangência, há uma sutil diferença quando se tomam decisões com base nessa posição: nos casos legais, deve-se estar muito certo (usualmente com probabilidade maior que 95% ou 99,9%) de que o verdadeiro valor do mensurando está ACIMA do permitido.
Entretanto, no que se refere a uma especificação de um produto, deve-se estar certo (usualmente com probabilidade maior que 95%) de que o verdadeiro valor do mensurando está ABAIXO de uma determinada especificação. O procedimento adotado é relatar os resultados afirmando que a amostra contém “não menos que o valor “C – U””, nas situações em que a especificação é uma concentração máxima admissível.
O conceito de “faixa de proteção” nos casos legais
Considere-se o seguinte: um motorista foi parado, fez o teste com o etilômetro, sendo reprovado. Foram retiradas amostras de sangue, cujo resultado a respeito da concentração de etanol foi de (6,1 ± 0,09) dg/L (adotando-se k=2).
Sabendo-se que o limite máximo permitido é de 6 dg/L, o motorista deve ser indiciado pelo crime previsto no art. 306 do CTB? Nesses casos legais, deve-se estar muito certo (com probabilidade maior que 99%) de que o verdadeiro valor do mensurando está ACIMA do máximo permitido.
Por essa razão, determina-se um LIMITE DE DECISÃO ACIMA do limite superior de especificação, de acordo com a seguinte expressão:
Limite de decisão LD = Limite superior de especificação LSE + k.u,
onde:
k é o valor da abscissa t, unilateral, da distribuição de Student; se usada a distribuição de Gauss, k=1,65 para uma probabilidade de conformidade de 95% e k=3,09 para uma probabilidade de conformidade de 99,9%, e
u é a incerteza padrão, calculada a partir da incerteza expandida por u = U/k. onde agora k é dado pela memória de cálculo da incerteza de medição.
O valor k.u denomina-se faixa de proteção, ilustrada pela Figura 4.
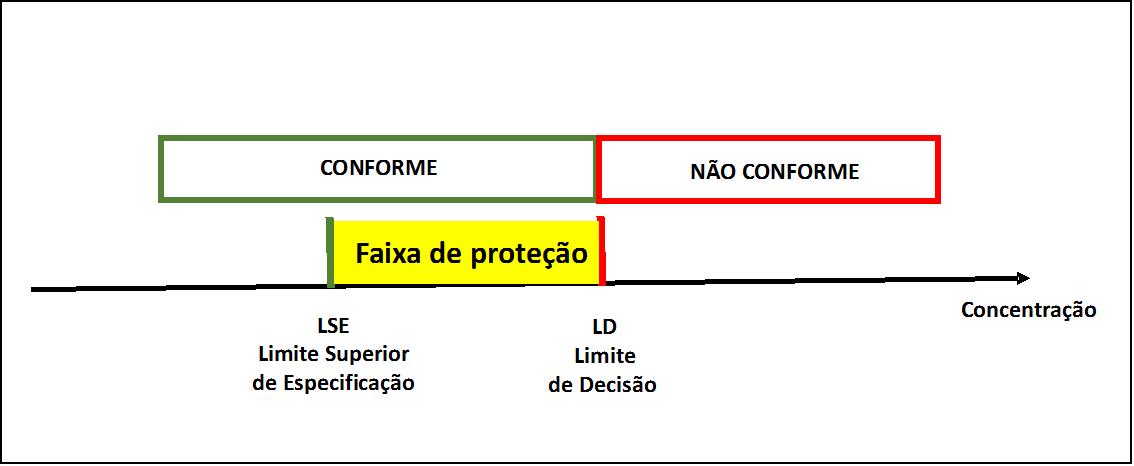
Figura 4 – Conceito de faixa de proteção para limite superior nos casos legais
Conclusão: nos casos legais, um resultado deve ser considerado NÃO
CONFORME somente se o Limite de Decisão for ultrapassado.
Retornando à situação do motorista que foi parado, fez o teste com o etilômetro, sendo inicialmente reprovado, e cuja análise de sangue foi de (6,1 ± 0,09) dg/L (adotando-se k=2). Sabendo-se que o limite máximo permitido é de 6 dg/L, o motorista deve ser penalizado?
Neste caso, primeiramente deve-se determinar o valor de u. Para uma incerteza expandida U=0,09 dg/L com k=2, tem-se que u = U/k = 0,09/2 dg/L = 0,045 dg/L.
Após, o LD = LSE + k.u. Como nada se sabe a respeito do tamanho da amostra, adota-se o k da distribuição de Gauss; então, para 95% de confiança, k=1,65 e
LD (dg/L)= (6,00 + 1,65 x 0,045) dg/L = (6,00 + 0,07) dg/L = 6,07 dg/L.
Como 6,1 dg/L ultrapassa o Limite de Decisão, com 95% de certeza, o motorista deve ser penalizado.
Considere, agora, uma certeza de 99,9%. Nesse caso, k = 3,09 e
LD (dg/L)= (6,00 + 3,09 x 0,045) dg/L = (6,00 + 0,18) dg/L = 6,18 dg/L.
Como 6,1 dg/L não ultrapassa o Limite de Decisão, com 99,9% de certeza, o motorista não deve ser penalizado, agora com uma certeza de quase 100%.
A Resollução 432 do CONTRAN não estabelece qual probabilidade deve ser usada (95% ou 99%) para o limite de decisão, nem estabelece a maneira de cálculo desse limite com base nessa faixa de proteção.
O conceito de “faixa de proteção” nos casos comerciais
Considere que a fração de um analito em uma determinada amostra é 1,82 mg/kg com uma incerteza expandida igual a 0,20 mg/kg para k=2. Se o limite é, no máximo, 2,00 mg/kg, essa amostra pode ser considerada conforme?
A decisão tomada usualmente é a seguinte: se o resultado está abaixo de 2,00 mg/kg, ele é CONFORME; caso contrário, NÃO CONFORME.
Entretanto, no que se refere a uma especificação de um produto, deve-se estar certo (com probabilidade maior que 95%) de que o valor do mensurando está ABAIXO desse limite superior, o que conduz a um LIMITE DE DECISÃO ABAIXO do limite superior de especificação, de acordo com o seguinte:
Limite de decisão LD = Limite superior de especificação LSE – k.u,
onde:
k é o valor da abscissa t, unilateral, da distribuição de Student; se usada a distribuição de Gauss, k=1,65 para uma probabilidade de conformidade de 95% e k=3,09 para uma probabilidade de conformidade de 99,9%, e
u é a incerteza padrão, calculada a partir da incerteza expandida por u = U/k. sendo k fornecido pela memória de cálculo da incerteza de medição.
O valor k.u igualmente se denomina faixa de proteção, ilustrada pela Figura 5.
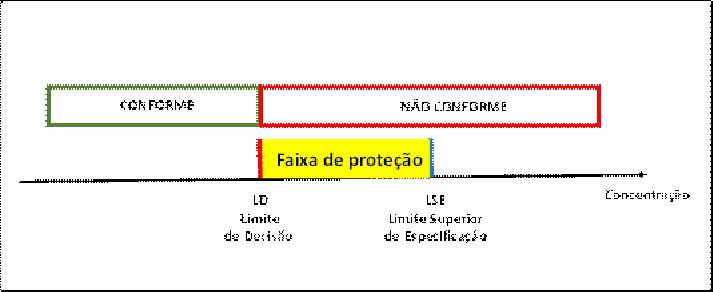
Figura 5 – Conceito de faixa de proteção para limite superior nos casos comerciais
Como conclusão, pode-se afirmar que, também nos casos comerciais, um resultado deve ser considerado NÃO CONFORME somente se o Limite de Decisão for ultrapassado.
Retornando ao exemplo numérico do analito, primeiramente deve-se determinar o valor de u. Para uma incerteza expandida U=0,20 mg/kg com k=2, tem-se que u = U/k = 0,20/2 mg/kg = 0,010 mg/kg.
Após, o LD = LSE – k.u. Como nada se sabe a respeito do tamanho da amostra, adota-se o k da distribuição de Gauss; então, para 95% de confiança,
LD (mg/kg)= (2,00 – 1,65 x 0,10) mg/kg = (2,00 – 0,165) mg/kg = 1,835 mg/kg.
Como 1,82 mg/kg, resultado da fração da massa de cádmio, é menor que o Limite de Decisão, com 95% de certeza, a amostra pode ser considerada CONFORME, por ter uma fração abaixo do limite superior de especificação.
Somente limite inferior de especificação para o valor da amostra
O raciocínio quando se tem somente o limite inferior de especificação é semelhante ao do somente limite superior. Nesse caso, para determinar os Limites de Decisão, as expressões são as seguintes:
nos casos legais:
Limite de decisão LD = Limite inferior de especificação LIE – k.u,
nos casos comerciais:
Limite de decisão LD = Limite inferior de especificação LIE + k.u.
Limites inferior e superior de especificação para o valor da amostra
Quando há os dois limites, o valor de k passa a ser o valor da abscissa t, bilateral, da distribuição de Student; se usada a distribuição de Gauss, k=1,96 para uma probabilidade de conformidade de 95% e k=3,27 para uma probabilidade de conformidade de 99,9%.
As expressões para determinar os Limites de Decisão, as expressões são as seguintes: nos casos legais, as faixas de proteção para os limites inferior e superior são dadas por (Figura 6):
Limite de decisão LD = Limite inferior de especificação LIE – k.u
Limite de decisão LD = Limite superior de especificação LIE + k.u,
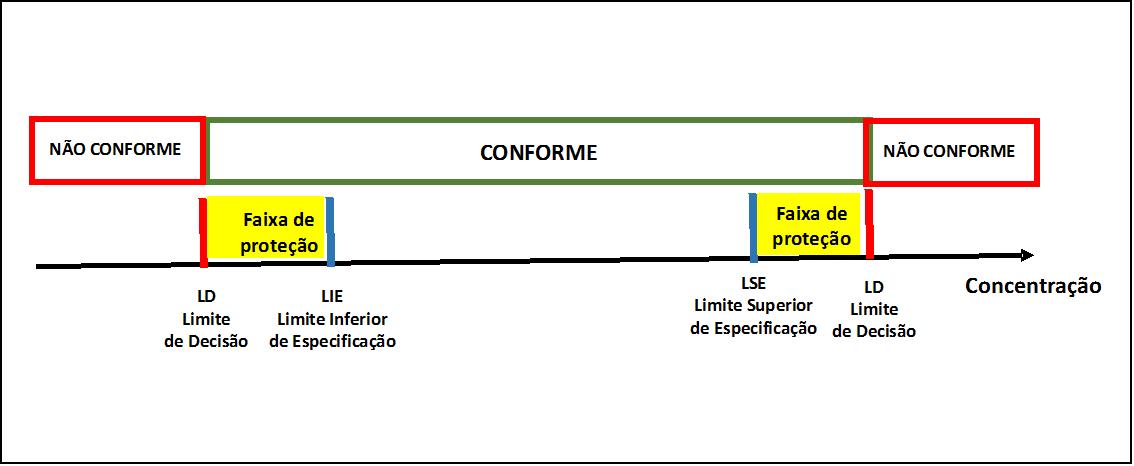
Figura 6 – Conceito de faixa de proteção para limites inferior e superior nos casos legais
Nos casos comerciais, as faixas de proteção para os limites inferior e superior são dadas por (Figura 7):
Limite de decisão LD = Limite inferior de especificação LIE + k.u
Limite de decisão LD = Limite superior de especificação LIE – k.u,
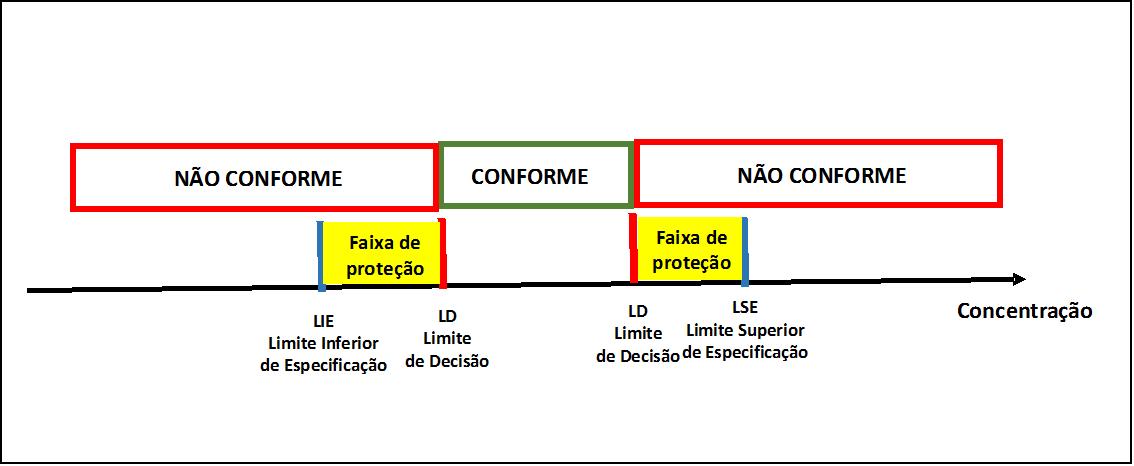
Figura 7 – Conceito de faixa de proteção para limites inferior e superior nos casos comerciais
O conceito de “faixa de proteção” para o desvio padrão
Diferentemente da faixa de proteção quando se estuda o valor de uma amostra da população, para o desvio padrão tem-se apenas o limite superior, porque, em estatística deseja-se ter variabilidade mínima, ou seja, o importante é apenas o limite superior de especificação, com uma faixa de proteção de se estar certo (usualmente com probabilidade maior que 95%) de que o verdadeiro valor do desvio padrão está abaixo do máximo desvio padrão permitido (MDPP).
A Figura 8 ilustra o relacionamento entre o MDPP e o limite de decisão.
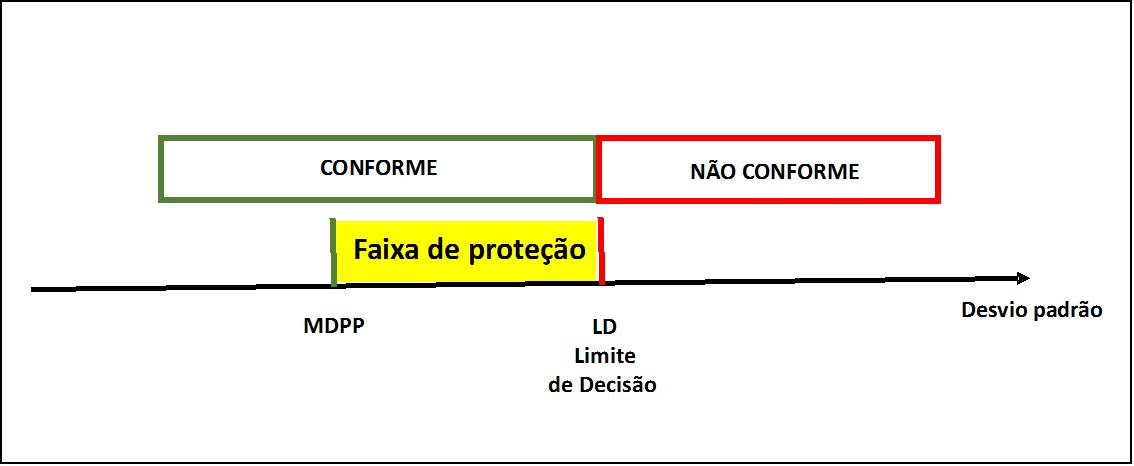
Figura 8 – Faixa de proteção para o desvio padrão da população
No caso do valor da população, essa faixa de proteção é igual a um certo número de desvios padrão (k,u). No caso do desvio padrão da população, o conceito é semelhante, A distância entre o MDPP e o LD é igual a um certo número de desvios padrão. No caso do valor da população, determinava-se o LD somando-se k.u ao LSE:
LD = LSE + k.u.
Entretanto, no caso do desvio padrão, não pode ser feita essa soma direta, porque os cálculos são realizados com as variâncias e o relacionamento passa a ser do seguinte modo:
LD2= k.MDPP2
Para se poder determinar o valor do LD, tem-se o valor de MDPP, mas não o de k. Entretanto, k= LD2MDPP2.
O valor de k é o resultado da divisão de duas variâncias, fração que é modelada pela distribuição F de Snedecor. Com base nessa distribuição, determina-se o valor da abscissa k que limita à direita da distribuição F uma probabilidade de 5% (equivalente a ter-se 95% de probabilidade à esquerda dessa abscissa), com graus de liberdade do numerador igual ao tamanho da amostra menos 1 e graus de liberdade do denominador igual a infinito, por ser o MDPP admitido como sendo o ideal da população.
Determinado o valor de k, finalmente chega-se ao valor do LD:
LD= k MDPP
Exemplo numérico para a “faixa de proteção” para o desvio padrão
Após 20 medições em um ensaio, até quando se deverá considerar uniforme a variabilidade dessas medições, ou seja, a partir de qual valor o desvio padrão deverá ser rejeitado?
Nesse caso, n = 20, e os graus de liberdade são 19. No Excel, determina-se o valor de k = 1,586501461 na distribuição F, conforme ilustra a Figura 9.
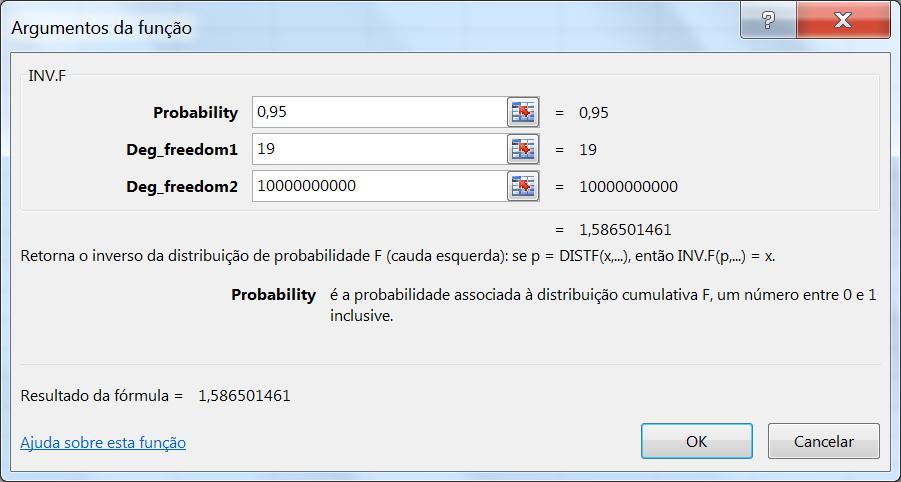
Figura 9 – Determinação do valor de k
Extraindo-se a raiz quadrada de k, tem-se que: 1,586501461= 1,259564, aproximado para 1,26. Finalmente, LD = 1,26 MDPP, ou seja, decide-se rejeitar o valor do desvio padrão se esse for maior que 1,26 vezes o MDPP.
Paulo Afonso Lopes é estatístico e membro da Academia Brasileira da Qualidade (ABQ) – pauloafonsolopes@uol.com.br





